OFBiz 是 ERP, CRM, eCommerce, SCM, MRP, … 以 Apache 授權的企業自動化軟體。之前可能不太容易上手, 一方面這種軟體需要關注的層面太多, 另一方面沒有中文化(有簡體中文)。
以上在這兩週有些改變。上週(11/18) Bakker 先生提供了快速設定的方式(r1036323), 包含: 公司, 倉儲, 商店, 電子商務網站, 第一位客戶, 第一筆產品 … 只要走過幾個 Web 畫面就可完成 OFBiz 基本資料設定。而這週中文化進入 trunk (r1039574), 應該能降低語言的隔閡。
大部分這類軟體要設定 網站伺服器,資料庫以及系統本身。而 OFBiz 由於 Java 語言的優勢, 嵌入了網站伺服器與資料庫, 只要一個指令就可啟動, 假使需要也可用常見的網站伺服器或資料庫替代。除了降低入門門檻, 同時也具備擴充性。
更多的 OFBiz 介紹可參考: 什麼是 OFBiz, 專案概觀 (各模組介紹), OFBiz 適合我嗎?
下面把 OFBiz 在 Windows 完整安裝過程 (從下載檔案開始), 包含必要的修正, 並簡單示範了銷貨訂單, 採購訂單的建立與使用 … 做成影片放到 Youtube 頻道中 ... OFBiz 線上教學。
2010/11/27
2010/11/13
應用開發的簡化
容易的方式
雖然常把實用新穎的技術簡化, 想辦法放入既有系統中, 讓夥伴、客戶都能上手使用, 但現實中卻還是不夠。前幾天幫客戶除錯, 看問題時, 才知道他們做了什麼 … 有點類似 Web Services (偽), 卻是用 PHP。他們在生產過程中, 要把某個事件記錄在另一個資料庫。當然用 PHP 沒什麼問題, 只是把所有執行相關工作都寫在一個檔案裡頭的做法, 很明顯是從書上抄下來的範例, 再改一改的成果。
對許多人來說, 書上有類似的範例, 能照本宣科就拿來用就好。這大概是某些語言長年佔據 排行榜 的原因, 但時至今日這股『只要能動』的風潮漸漸改變。在 Web 時代大部分拿 SQL 就直接用, 到了 Web Services 時代, 分工愈來愈細, 要求愈來愈多, 許多程式的運作都以物件為基礎。並非談物件的優劣, 而是評估現實中若使用物件比 SQL 方便, 比如資料的呈現(xml, json), 處理(鷹架), 以及檢核這些作業, 自然而然趨勢也跟著改變。
這裡還有一個關鍵點, 以上面出問題的 PHP 來說, 不管怎樣只要一個檔案就做完收工。原有系統在程式方面雖然也能簡單做到, 但要連到他們內部使用的資料庫(MySQL)這種配置就不太容易。因為原系統採 N 階層架構, 要多接個資料庫, 雖然可做到, 但得更動不少層。
或許從仿 PHP 單一檔案開發起個頭, 比較容易些。
簡單的實現
PHP 帶領 LAMP 的風潮, 在 約定優於配置 之前, 受到許多開發人員喜愛。著重四個方面: 簡單編寫, 簡單散佈, 本機開發, 便宜且到處可託管。除了最後一個外, 前三項直接讓開發的人獲得好處。預設與 MySQL 搭配(以 5.3.3 來說, 還有 PostgreSQL, Oracel, Sqlite), 因此只要資料庫能夠運作, 程式就能寫, 能動, 能測。程式執行後, 也能立即從資料庫看看結果是否正確。再複雜些的系統, 除了語言本身, 還得準備更多暖身課程。
在今天之前, 也一直覺得 PHP 劃下簡單的境界, 是無法挑戰的。原本的 Groovy 知識, 只想做到很接近, 但查了查資料, 發現結果還不錯。
前提是有個 MySQL 在正常運作, 假設有資料庫 mydb 以及表格 mytbl 如下:
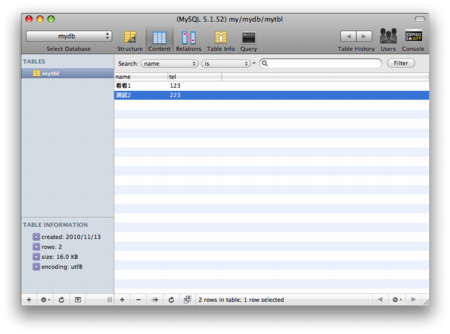
有兩欄(name, tel), 以及兩列資料。
先確定裝妥 JDK 1.6 以上版本, 再到 Groovy 首頁 下載 1.7 之後版本, 然後執行 bin/ 目錄下的 groovyConsole 能直接寫程式。
拷貝、貼上程式碼:
@Grapes([
@Grab('mysql:mysql-connector-java:5.1.13'),
@GrabConfig(systemClassLoader=true)
])
import groovy.sql.Sql
def dbUrl="jdbc:mysql://localhost/mydb?useUnicode=yes&characterEncoding=UTF-8"
def driverClass="com.mysql.jdbc.Driver"
def sql=Sql.newInstance(dbUrl,"root","root",driverClass)
sql.eachRow("select * from mytbl") {
println it
}
注意, 資料庫位置 localhost, 名稱 mydb, 帳號/密碼 root/root, 還有表格名稱 mytbl 可能需要置換。然後選擇執行, 可用工具列右邊屬來第二個圖示, 或選單裡頭 Script/Run。第一次可能久一點, 因為缺少連接 db 的程式庫(不像 PHP 有附加), 要花些時間下載, 之後就正常。LAMP 要義的第一項簡單編寫, 第三項本機開發, 可順利達成。整個結果, 應該和下圖差不多:
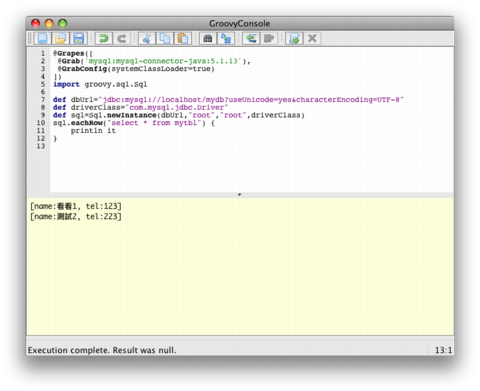
除了讀取資料庫, 其它新增、更新、刪除的 SQL 也都有, 請參考 Groovy SQL。確定沒問題, 就存檔保留。
不過這時候或許有人會問: PHP 在命令列(command line)下執行很快的, Groovy 那能比? 那請試試 GroovyServ, 雖然有點作弊, 但就像 IE 比其他瀏覽器快, Office 比其他工具快, 差不多就是那種的方式 …
換不同資料庫, 應該只要改上面截圖中第 2 列程式庫, 第 7 列連接資料庫網址, 第 8 列資料庫套件名稱, 可能再加上第 9 列的帳號、密號, 其它步驟類推即可。
以上示範, 算真正的單一檔案寫完收工, 也簡單到少有的地步。
那放到網站是否很複雜?
在 Java 使用 Tomcat 會比 LAMP 中 Apache 容易。相同方式 tomcat 5, 6, 7 版本可通用, 這裡以 tomcat 6.0.29 示範。下載後解開, 把長長的目錄改為 tomcat6/。
在 tomcat6/ 下的 webapps/ 裡頭建 groovy/ 目錄, 再建 WEB-INF/。
把 Groovy 1.7 的 lib/ 複製到 WEB-INF/ 裡頭。
在 WEB-INF/ 增加 web.xml 檔案, 內容如下:
<web-app xmlns="http://java.sun.com/xml/ns/javaee" version="2.5">
<display-name>Groovy Web Apps</display-name>
<servlet>
<servlet-name>Groovy</servlet-name>
<servlet-class>groovy.servlet.GroovyServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>Groovy</servlet-name>
<url-pattern>*.groovy</url-pattern>
</servlet-mapping>
</web-app>
而把上面讀取資料庫的 groovy 程式, 前幾列 @Grab 改一些 (有點尷尬, 之前寫法在 Web 不能用), 不過下列是通用的。(日後應該會針對此點修補 @Grab 才是)
ClassLoader.systemClassLoader.class.name = 'groovy.lang.GroovyClassLoader'
groovy.grape.Grape.grab(classLoader:ClassLoader.systemClassLoader
,group:'mysql', artifact:'mysql-connector-java', version:'5.1.13')
import groovy.sql.Sql
def dbUrl="jdbc:mysql://localhost/mydb?useUnicode=yes&characterEncoding=UTF-8"
def driverClass="com.mysql.jdbc.Driver"
def sql=Sql.newInstance(dbUrl,"root","root",driverClass)
sql.eachRow("select * from mytbl") {
println it
}
整個做法的結果應該和下圖相同:

以上方法做完, 執行 tomcat 6 … 一般用 bin/catalina.sh run 即可。
此時瀏覽器看到結果如下:

單機寫完應用程式, 執行驗證完後, 隨即放上網站目錄去, LAMP 要義第二項的簡單散佈也可達陣。
簡單還要更簡單
原先想寫關於資料庫程式遷徙到 grails 的方式, 因為客戶的問題轉到另一個題目上, 與 PHP 的某種(通用?)做法比劃一下。除此之外, 還有更積極的意義 … PHP 固然是寫資料庫和網頁程式的主流, 其相關資源可略窺一二。但 Java 連接的 IT 資源更廣泛, 像負責生產管理的 MES, 或財務處理的 AIS, 都由於加上 Groovy 的協助, 讓原本的系統有更大彈性, 也讓部份客製門檻降低, 例如一些報表、檢核的作業讓更多 IT 人員參與。可以想像一下 … 上面 SQL 資料讀入與 Web 輸出部份, 換成來自不同系統流程的資料, 以及 csv, xml, xls 或 pdf 輸出, 輔以適當的權限與稽核, 就可讓原本要獨立開發的程式變成簡單的腳本擋。
且如同 PHP 一般即改即用, 很簡單的滿足許多需求。
參考
- 石頭閒語的 軟體開發之建置風險的故事
- Groovy SQL 用 Groovy 寫 SQL 程式也可以行雲流水
- GroovyServ 加速 Groovy 程式執行
- Groovy Servlet 把應用程式放上網站
- Groovy Grape 對程式庫做了一些神祕的事情
2010/11/08
應用系統的版本管理
一段歷史
經過幾年軟體版本管理工具爆炸性的競合, 如果不考慮控制的問題, 我們可以自由選用 subversion(svn), mercurial(hg) 以及 git。svn 存在時間最早, 在有一些歷史的專案和中小公司比較常見; hg 由於簡單明確, 大型源碼社群如 sourceforge, codeplex, google code 普遍接受; 而 git 強大穩定, 則是技客首選。
這三者陸續在用, 雖然深淺各有不同, 從歷史角度來看: 最早通用的 cvs 是管理檔案版本, 所以會有 v1.0, v1.1, v1.2, ….。svn 側重整個專案版本, 標示版本以整個儲存庫為準 r123, r223, r323, … (r=revision)。大概是 cvs 時期一個檔案就可做完一件事, 到了 svn 得靠一堆檔案 … 請參考『軟體工程師的進化』一文。
到了 dvcs(hg, git) 回歸功能面管理, 版本像是 229a46966a72, 13a7d2806d50, 64d88c389b67, … 的 uuid。意義不再是檔案版本編號(v1.0), 或由儲存庫變更序號(r123)做認定。應該沒有人可從 dvcs 裡版本號碼看出任何意義。一方面在每次提交版本(commit)輔以適當註解, 而整體來看, 端視儲存庫擁有者認定版本的意義。因為是 dvcs … 只要有心, 人人都可以是儲存庫擁有者 … peace!
對一個專案來說, 針對檔案變更追蹤是過小, 像流行的 MVC (Model-View-Controller)在概念上就跨了三層。若針對儲存庫變更追蹤又太大, 變更頻繁的話, revision 就如同雪片般, 好看是好看, 但一般也只是好看。因此, dvcs 當是比較符合趨勢的選擇。
一種問題
交待完歷史, 回頭看主題。假設專案有源碼要管理, 這個應用系統是承上啟下, 也就是依據上游源碼為基礎, 提供下游客戶穩定、加強、或客製的版本。是種常見模型:


上游儲存庫 UR - Upstream Repository
我的儲存庫 MR - My Repositroy
源碼儲存庫畢竟是技術人員才會接觸到, 大部分狀況以策略解決: 有時將上游源碼設定為程式庫, 簡化問題; 或以廠商分枝(Vendor Braches)將上游源碼納入專案; 而產品類專案, 可忽略 n 個客戶問題。
但如果使用開放源碼 CMS, CRM 或 ERP 這類應用為主的系統, 上游持續加強版本, 下游因應需求不斷變更 … 會爆炸的點大概就是位居中間的儲存庫。
在網路上, 看到相關問題討論有:
- 非官方 hg 流程 中 Offsite working on dynamic websites。其中『Upgrading Drupal with Git』(部落格已落幕, 可參考 archive.org 資料)。
- 也是 drupal 開發, 教學視訊 Git With Drupal 7。
- opentaps(ERP) 的建議 Managing Customizations with Upgrades, 大抵是分為四個層次: a. 瞭解現有的, 將異動最小化 b. 貢獻源碼, 免除版本差異, 透過社群改進 c. 獨立應用程式在特定目錄下 d. 若修改核心及社群不接受的源碼, 得注意合併問題。最末項不建議, 因容易出包。
上面第三項 "在特定目錄下" 放應用程式, 是大部分應用系統普遍的做法, 像 SugarCRM 也有類似的機制。
通常專案會設定上游的版本, 但長期提供服務, 必然會面對上游版本變更。而下游的需求, 投入行業時間夠久, 一般也會有共通方式解決, 例如提供一個檔案上傳或流程整合的功能, 應該也不希望一家處理過版本提升後, 還得要處理其他家客戶相同問題。
技術上, 沒有通用做法的話, 能抑制爆炸的源碼就大概只有爆炸的肝。(以爆制爆?)
一項解法
如果著眼於儲存庫, 所有問題都成為一團。首先區分上游變更, 與下游需求這兩個變動的來源。其他像共通功能的開發, 問題的修正, … 先納入下游需求。
再來, 如版本管理的演化(csv → svn → dvcs), 因時制宜般, 上游變更以分枝(branches)處理, 下游需求以變更佇列(patchs queue)對付, 再建立一個儲存庫負責照拂需求的變更佇列, 是為『變更儲存庫』。


變更儲存庫PR - Patch Repository
在手上實際 ERP 案例中, 上游儲存庫每個月大約有 800kb 左右的差異檔(diff), 而變更佇列除了中文化有 5mb 的差異檔, 其他加起來不到 300kb。每月同步上游儲存庫後, 再更新變更佇列, 也就是 UR 與 PR 會有版本對應的關係。只要 UR 與 PR 同步後, 就可一體適用其他相同系統的客戶。節省下的資源可專注差異化部份。
一方面是變更的大小與不同機制的搭配, 另一方面是變更佇列對每項修補差異的處理, 比分枝來得直覺。例如把中文化和其他修補一起放入同一個分枝中, 當上游版本更新, 要合併到分枝時, 假使自動合併無效, 要看到檔案才能處理, 同時可能也要處理 API 差異之類的。簡單來說, 就是要有經驗的工程師才能處理版本合併的事務。如果是以變更佇列處理的規劃, 就很方便分工, 中文化部份安排通中/英文, 細心的工程助理打點即可。
參考
- 軟體工程師的進化 (原文: http://www.infiltec.com/j-h-wrld.htm)
- Distributed Version Control Systems
2010/08/31
Bonjour 你好
Bonjour 是 蘋果 版 zeroconf 免設定網路產品, 協助使用者更容易用網路。
雖然 Bonjour 與 zerconf 目標是各種網路服務, 這裡的範圍限制在網頁。免設定網路目前解決三個問題: 設備(名稱)的IP(網路位置)指定, 自動取得名稱與IP關連(廣播法 mDNS), 自動取得網路服務(dns-sd)。
技術上有點繞口, 實務上就如同一個 Wiki 工具 Voodoo Pad 寫妥許多內容, 要分享只要點選 Start 按鈕:

其他人利用 Safari 的書籤頁就可以看到:

不用網址、埠號、目錄, 看到名稱點下去, 立即瀏覽網頁。
除 Safari 外, Firefox 的 BonjourFoxy Plug-in 有相同功能, 目前支援 Windows 與 OSX。(Windows 安裝前須先裝妥 Apple Bonjour 套件)

BonjourFoxy 另附有 Bonjour Browser 可觀察 dns-sd 詳細內容:

寫到這裡都是使用者操作面上。手上也有許多各式各樣網頁, 是否能建立 Bonjour 項目瀏覽資料?
最簡單方法大概利用 OSX 中 /usr/bin/dns-sd (Bonjour 套件) 在 Terminal 下指令:
會佔住 Terminal, 要結束就直接按 ctrl-C。
dns-sd 除了為本機建立 Bonjour 服務項目, 也可代理(Proxy):
注意 path 可指定 URL 主機、埠號後的部份。
分享網址除了剪貼、美味書籤、社群工具, Bonjour 也是個方式, 而且是立即的。
雖然 Bonjour 與 zerconf 目標是各種網路服務, 這裡的範圍限制在網頁。免設定網路目前解決三個問題: 設備(名稱)的IP(網路位置)指定, 自動取得名稱與IP關連(廣播法 mDNS), 自動取得網路服務(dns-sd)。
技術上有點繞口, 實務上就如同一個 Wiki 工具 Voodoo Pad 寫妥許多內容, 要分享只要點選 Start 按鈕:
其他人利用 Safari 的書籤頁就可以看到:
不用網址、埠號、目錄, 看到名稱點下去, 立即瀏覽網頁。
除 Safari 外, Firefox 的 BonjourFoxy Plug-in 有相同功能, 目前支援 Windows 與 OSX。(Windows 安裝前須先裝妥 Apple Bonjour 套件)
BonjourFoxy 另附有 Bonjour Browser 可觀察 dns-sd 詳細內容:
寫到這裡都是使用者操作面上。手上也有許多各式各樣網頁, 是否能建立 Bonjour 項目瀏覽資料?
最簡單方法大概利用 OSX 中 /usr/bin/dns-sd (Bonjour 套件) 在 Terminal 下指令:
$ dns-sd -R "Plone" _http._tcp "" 7070 "Plone 4 Here"
會佔住 Terminal, 要結束就直接按 ctrl-C。
dns-sd 除了為本機建立 Bonjour 服務項目, 也可代理(Proxy):
$ dns-sd -P "Zoo Keeper" _http._tcp local 80 hadoop.apache.org "" path=/zookeeper "你好 Zoo Keeper"
注意 path 可指定 URL 主機、埠號後的部份。
分享網址除了剪貼、美味書籤、社群工具, Bonjour 也是個方式, 而且是立即的。
2010/08/27
ZKFuse 與 macfuse
zkfuse 可能會被歸在玩具類, 是網路控制中心 ZooKeeper 把資料暴露在 FUSE 下。但與 macfuse 不符(API 差異), 就游進去解決一下 ...
參考網誌 HowTo Mount ZooKeeper using FUSE 的做法。
zkfuse 需要 fuse(macfuse 2.0.3), boost, log4cxx ... 都用 macports 裝妥。
取得 zookeeper-3.3.1.tar.gz 解開到 <zookeeper3>。
按照/src/c/README 編 zookeeper:
到 zkfuse/ 目錄下:
由於 macfuse 與 fuse 差異, 修改 src/mutex.h:
修改 src/zkfuse.cc:
改完繼續做出 zkfuse:
產生 src/zkfuse ... 然後繼續: (開始用 zkfuse 前要先啟動 zookeeper)
開另一個終端機看 123/ 目錄內容:
參考網誌 HowTo Mount ZooKeeper using FUSE 的做法。
zkfuse 需要 fuse(macfuse 2.0.3), boost, log4cxx ... 都用 macports 裝妥。
取得 zookeeper-3.3.1.tar.gz 解開到 <zookeeper3>。
按照
$ cd zookeeper3
$ ant compile_jute
$ cd src/c/
$ ./configure
$ make
$ sudo make install
(預設安裝到 /usr/local/include/ 與 /usr/local/lib/)
到 zkfuse/ 目錄下:
$ cd ../contrib/zkfuse/
$ autoreconf -if
$ export LDFLAGS="-L/usr/local/lib -L/opt/local/lib"
$ export CXXFLAGS="-I/opt/local/include -I/usr/local/include"
$ export LIBS="-lzookeeper_mt"
$ ./configure
由於 macfuse 與 fuse 差異, 修改 src/mutex.h:
--- mutex.h.original 2010-08-27 10:38:10.000000000 +0800
+++ mutex.h 2010-08-27 10:38:20.000000000 +0800
@@ -34,7 +34,7 @@
public:
Mutex() {
pthread_mutexattr_init( &m_mutexAttr );
- pthread_mutexattr_settype( &m_mutexAttr, PTHREAD_MUTEX_RECURSIVE_NP );
+ pthread_mutexattr_settype( &m_mutexAttr, PTHREAD_MUTEX_RECURSIVE );
pthread_mutex_init( &mutex, &m_mutexAttr );
}
~Mutex() {
修改 src/zkfuse.cc:
--- zkfuse.cc.original 2010-08-27 10:28:37.000000000 +0800
+++ zkfuse.cc 2010-08-27 10:30:01.000000000 +0800
@@ -27,7 +27,7 @@
extern "C" {
#include
-#include
+// #include
}
#include
#include
@@ -4171,16 +4171,17 @@
int zkfuse_lock(const char *path, struct fuse_file_info *fi, int cmd,
struct flock *lock)
{
- (void) path;
- return ulockmgr_op(fi->fh, cmd, lock, &fi->lock_owner,
- sizeof(fi->lock_owner));
+ return 0;
+// (void) path;
+// return ulockmgr_op(fi->fh, cmd, lock, &fi->lock_owner,
+// sizeof(fi->lock_owner));
}
static
void init_zkfuse_oper(fuse_operations & fo)
{
- memset(&fo, 0, sizeof(fuse_operations));
+// memset(&fo, 0, sizeof(fuse_operations));
fo.getattr = zkfuse_getattr;
fo.fgetattr = zkfuse_fgetattr;
// fo.access = zkfuse_access;
@@ -4204,7 +4205,7 @@
fo.open = zkfuse_open;
fo.read = zkfuse_read;
fo.write = zkfuse_write;
- fo.statfs = zkfuse_statfs;
+// fo.statfs = zkfuse_statfs;
fo.flush = zkfuse_flush;
fo.release = zkfuse_release;
fo.fsync = zkfuse_fsync;
改完繼續做出 zkfuse:
$ make
產生 src/zkfuse ... 然後繼續: (開始用 zkfuse 前要先啟動 zookeeper)
$ mkdir 123
(要 mount 的入口點)
$ src/zkfuse -z localhost:2181 -m 123 -d
(要加 -d, 否則不能用 ... 但終端機會被佔住)
開另一個終端機看 123/ 目錄內容:
$ ls zookeeper3/src/contrib/zkfuse/123
zookeeper
2010/08/25
Avro 的使用與 Groovy Builder
Avro 是動態型別的資料序列化工具, 協助資料存放保留, 主要是讓網路化的應用程式有效率的溝通。如同使用語言設計模組溝通一般會透過界面方式, 在網路的服務常有著不同語言的實作, Avro 提供這些服務溝通的方式。
定義網路溝通的是通訊協定(Protocol), Avro 利用 JSON 定義通訊協定。
協定內包含有若干具名(name)的訊息(Protocol.Message), 每個訊息含有 3 種型態內容: 要求(Requst), 回覆(Response), 還有錯誤(Errors)。這些內容都以綱目(Schemas)定義內容的組成。
Avro 協助按綱目組成傳送的訊息。這裡有兩個關鍵: 一是組成, 一是傳送。
組成部份請參考 Patrick Hunt 先生的快速開始使用 Avro 範例 中可看出 python 與 ruby 都用語言本身的 collection 組成; 而 Java 則用 GenericData 套件。
而傳送方面 Avro 有 HTTP 與 Socket 兩種通用方式, 服務端是 Server, 使用端是 Transceiver。如果用訊息服務(MOM)或搭配既有SOA,ESB系統, 就得抓訊息產生結果來操作。(在 Java 用 GenericRequestor, GenericResponder 中的 read/write 方法)
以 Groovy 與上面 Python 範例對連:
其中 import 群下的 def avpr = """......""" 是把 src/avro/mail.avpr 定義的通訊協定拷貝進去。
如果不想用嵌入式, 可改為類似 python 範例中的:
再做 Groovy 的 Server:
其中 respond(Protocol.Message msg, Object req) 的 req 為 GenericData.Record 在 Groovy 利用 GPath 直接操作相當便利。但客戶端用 GenericData 組成看起來頗辛苦, 想改用 Groovy Builder 式:
寫個 AvroGroovyBuilder.java 放在 github。 (注意: 目前沒處理 List)
使用端就可簡化成為:
定義網路溝通的是通訊協定(Protocol), Avro 利用 JSON 定義通訊協定。
協定內包含有若干具名(name)的訊息(Protocol.Message), 每個訊息含有 3 種型態內容: 要求(Requst), 回覆(Response), 還有錯誤(Errors)。這些內容都以綱目(Schemas)定義內容的組成。
Avro 協助按綱目組成傳送的訊息。這裡有兩個關鍵: 一是組成, 一是傳送。
組成部份請參考 Patrick Hunt 先生的快速開始使用 Avro 範例 中可看出 python 與 ruby 都用語言本身的 collection 組成; 而 Java 則用 GenericData 套件。
而傳送方面 Avro 有 HTTP 與 Socket 兩種通用方式, 服務端是 Server, 使用端是 Transceiver。如果用訊息服務(MOM)或搭配既有SOA,ESB系統, 就得抓訊息產生結果來操作。(在 Java 用 GenericRequestor, GenericResponder 中的 read/write 方法)
以 Groovy 與上面 Python 範例對連:
import org.apache.avro.Protocol
import org.apache.avro.util.Utf8
import org.apache.avro.ipc.HttpTransceiver
import org.apache.avro.generic.GenericData
import org.apache.avro.generic.GenericRequestor
def avpr = """
......
"""
def proto = Protocol.parse(avpr)
def trans = new HttpTransceiver(new URL('http://localhost:8080'))
def req = new GenericRequestor(proto, trans)
def message = new GenericData.Record(proto.getType('Message'))
message.put('to', new Utf8('wei'))
message.put('from', new Utf8('tcc'))
message.put('body', new Utf8('Hello 123'))
def params = new GenericData.Record(proto.messages.send.request);
params.put('message', message)
def ret = req.request('send', params)
println "Result: " + ret
其中 import 群下的 def avpr = """......""" 是把 src/avro/mail.avpr 定義的通訊協定拷貝進去。
如果不想用嵌入式, 可改為類似 python 範例中的:
def proto = Protocol.parse(new File('../avro/mail.avpr'))
再做 Groovy 的 Server:
import org.apache.avro.Protocol
import org.apache.avro.util.Utf8
import org.apache.avro.ipc.HttpServer
import org.apache.avro.generic.GenericData
import org.apache.avro.generic.GenericResponder
def avpr = """
......
"""
def proto = Protocol.parse(avpr)
class MyResponder extends GenericResponder {
public MyResponder(Protocol proto) {
super(proto)
}
public Object respond(Protocol.Message msg, Object req) {
return new Utf8("""Sent message ${req.message['to']}
from ${req.message['from']}
with body ${req.message['body']}""")
}
}
def res = new MyResponder(proto)
new HttpServer(res, 8080)
其中 respond(Protocol.Message msg, Object req) 的 req 為 GenericData.Record 在 Groovy 利用 GPath 直接操作相當便利。但客戶端用 GenericData 組成看起來頗辛苦, 想改用 Groovy Builder 式:
avro_builder.send { request {
message(to:'wei', from:'tcc', body:'Hello 123')
}}
寫個 AvroGroovyBuilder.java 放在 github。 (注意: 目前沒處理 List)
使用端就可簡化成為:
import org.apache.avro.Protocol
import org.apache.avro.ipc.HttpTransceiver
import org.apache.avro.generic.GenericRequestor
def avpr = """
......
"""
def proto = Protocol.parse(avpr)
def trans = new HttpTransceiver(new URL('http://localhost:8080'))
def req = new GenericRequestor(proto, trans)
def avro_builder = new org.tcchou.groovy.AvroGroovyBuilder(proto)
avro_builder.send { request {
message(to:'wei', from:'tcc', body:'Hello 123')
}}
def ret = req.request('send', avro_builder.params)
println "Result: " + ret
2010/08/10
Jailer 的使用
經常與資料庫為伍的開發者來說, 雖然 ORM 的普及解決大部分與 DB 溝通的問題, 但屬於型態上的。特別是常見的資訊系統, 很多工作直接與資料相關, 缺少實際資料根本是無以為繼。
以生產系統為例, 產品料表、流程定義與處置資料分由不同部門負責, 即便開發新的或調整 B2B, 缺乏這些資料還是無從下手。縱使 SA/SD 幾個單位走完, 最末還是要這些資料才好開工。
經歷過專案時程是上游廠商壓下游, 雛型只做一個段落就直接在正式環境運作 ... 邊進行、邊修程式、邊改資料的歲月真是折磨人。
前一陣子瀏覽到 http://jailer.sf.net 就看它閃耀著光輝。與資料整合(Data Integration)或 ETL 工具相比較, 這些傢私可能過大而不合用。
因為 jailer 只要關注兩件事: 首先定義表格(Tables)的相關性; 再來是抽取資料的條件。至於表格本身的定義 jailer 可抽取出來, 關連性雖然原則上可由鍵值決定, 但 jailer 也提供人工設定關連, 這點相當符合一般需求。
舉例來說 Order(1) -> Batch(N) ... 訂單關連到投產批是 1:N 關係; Batch(1) -> Job(N) ... 投產批與生產批也是 1:N 關係。其他與流程、處置、記錄相關資料零零總總, 這些關連都事先定義妥(大約有 10+ 個表格的關係)。日後只要指定投產批號, 就可拿到所有相關表格資料, 相當方便。
拿到資料的方式, 可選擇 SQL 直入測試資料庫; 或產生 Flat XML 與 http://www.dbunit.org 搭配使用。
以生產系統為例, 產品料表、流程定義與處置資料分由不同部門負責, 即便開發新的或調整 B2B, 缺乏這些資料還是無從下手。縱使 SA/SD 幾個單位走完, 最末還是要這些資料才好開工。
經歷過專案時程是上游廠商壓下游, 雛型只做一個段落就直接在正式環境運作 ... 邊進行、邊修程式、邊改資料的歲月真是折磨人。
前一陣子瀏覽到 http://jailer.sf.net 就看它閃耀著光輝。與資料整合(Data Integration)或 ETL 工具相比較, 這些傢私可能過大而不合用。
因為 jailer 只要關注兩件事: 首先定義表格(Tables)的相關性; 再來是抽取資料的條件。至於表格本身的定義 jailer 可抽取出來, 關連性雖然原則上可由鍵值決定, 但 jailer 也提供人工設定關連, 這點相當符合一般需求。
舉例來說 Order(1) -> Batch(N) ... 訂單關連到投產批是 1:N 關係; Batch(1) -> Job(N) ... 投產批與生產批也是 1:N 關係。其他與流程、處置、記錄相關資料零零總總, 這些關連都事先定義妥(大約有 10+ 個表格的關係)。日後只要指定投產批號, 就可拿到所有相關表格資料, 相當方便。
拿到資料的方式, 可選擇 SQL 直入測試資料庫; 或產生 Flat XML 與 http://www.dbunit.org 搭配使用。
2010/05/06
Closure under Groovy
// using closure under groovy
// to display all contains in directory
def getFiles = { dir, rtn ->
dir.listFiles().each { file ->
if (file.isDirectory()) {
getFiles(file, rtn)
} else {
rtn.call(file) // action
}
}
}
getFiles(new File('/Users/tcchou/Desktop/ewtek'), { file ->
println file.getAbsolutePath()
})